
1. Curriculum Learning
Bengio提出了课程学习的概念,来自于人类从易到难的学习过程:将数据看作模型所学习的内容的话,我们自然需要一个合理的课程(curriculum)来指导模型学习这些内容的方式。在课程学习中,数据被按照从易到难的顺序逐渐加入模型的训练集,在这个过程中训练集的熵也在不断提高(包含更多的信息)。
A model is learned by gradually including from easy to complex samples in training so as to increase the entropy of training samples.
课程学习的核心问题是得到一个ranking function,该函数能够对每一条数据样本给出其learning priority (学习该样本的优先程度)。一个确定的ranking function便能够确定一个“课程”,有更高rank的数据会被较早地学习。
一般特定问题的ranking function是靠直觉来定义的,这样的定义方法可能会存在偏差,不够科学,所以引出了self-paced learning。
2. Self-paced learning
Kumar在2010年提出self-paced learning,通过模拟认知机制,通过先学习简单的、普适性的知识,然后逐渐增加难度,学习更复杂、更专业化的知识课程学习。自步学习从选取最简单的数据子集开始,逐渐加入复杂的数据,从而减少熵值,训练出潜在的权重参数。基本思路是利用损失大小与难易程度之间的对偶关系进行对所学样本的加权。这种加权格式类似于引入隐含变量后的估计推断格式和EM算法格式,使得模型对于数据分布的学习更加稳健

SPL 通过在损失函数中引入变量 来表示样本是否被选择:
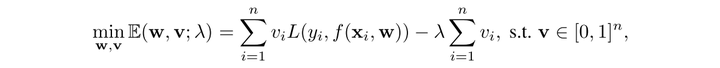
SPL将curriculum设计为学习的目标函数中的一个正则化项,SPL的优化目标即优化得到一组模型参数w与权重向量v,使得所有数据的加权Loss之和与负的权重向量v的L1范数最小(也存在同时使用L1L2范数的变体[3])。其中 λ 是一个控制参数,反映了当前学习所进行到的阶段(learning pace), 是调整步速的关键变量,
越小,表明模型还在训练的初始阶段,训练相对简单的样本,随着
增大,模型学习越来越多的样本。
直观来解释一下权重向量v,最常用的是binary (0/1)的形式:其实就是是否选择该数据进入训练/验证集。note that在Loss项前乘了因子vi,所以对于第i条数据,若vi=0则其产生的Loss对于该步的模型参数w更新没有影响。
Reference
- Bengio, Yoshua, et al. “Curriculum learning.” Proceedings of the 26th annual international conference on machine learning. ACM, 2009.
- Kumar, M. Pawan, Benjamin Packer, and Daphne Koller. “Self-paced learning for latent variable models.” Advances in Neural Information Processing Systems. 2010.
- https://zhuanlan.zhihu.com/p/55720313
- https://zhuanlan.zhihu.com/p/54025612


